
I Export PostgreSQL Queries to Google Sheets For Free. Here’s How

A couple of years ago, I wouldn’t have known that connecting a PostgreSQL database to Google Sheets could be this expensive.
Despite being a trivial problem, existing market solutions such as Zapier, KPIBees, etc. require us to pay a premium for it.
TL;DR: How to export PostgreSQL queries to Google Sheets via GitHub (and a little bit of Bash scripting).
Why Did I Need It
Here’s a little bit of context.
I maintain a tiny side project named Fareview — a commercial beer price monitoring tool that scrapes commercial beer data from Singapore e-commerce sites and stores it in a PostgreSQL database.
The summary of the data gathered is then synced daily to Google Sheets for users to view.
Instead of paying for a monthly premium, I’ve decided to use GitHub Action to help me with such a task for free.
Here’s How It Works
This method should also work with any other SQL databases (e.g. MySQL) with a CLI like psql.
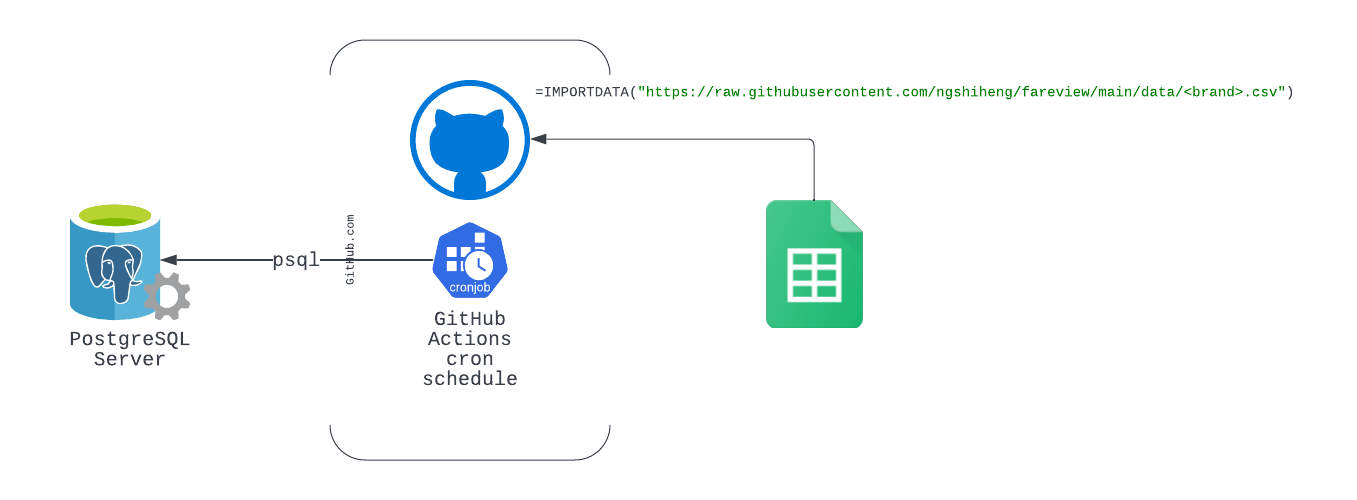
- Create a simple Bash script that uses Postgres client CLI (
psql) to run the SQL queries and output them in CSV file format from our PostgreSQL database server - Set up a GitHub Actions workflow that runs the Bash script in Step 1 and commits the generated file into our repository on a Cron schedule
- On Google Sheets, use the
=IMPORTDATA("<url-of-csv-file>")function to import our CSV data from our repository to our Google Sheets
It is important to note that the IMPORTDATA function updates data automatically at up to 1-hour intervals. In case you need a shorter interval use case, you may need to work around it.
Here Are the Steps To Do It
Bash Script
Depending on your use case, you may not even need a Bash script. For instance, you could just run the psql command as one of the steps within your GitHub Actions workflow.
Using a Bash script here provides more flexibility as you could also run this manually outside of GitHub Actions in case you need it.
This is the Bash script (generate_csv.sh) that I’m running:
#!/bin/bash
BRANDS=("carlsberg" "tiger" "heineken" "guinness" "asahi")
PGDATABASE="${PGDATABASE-fareview}"
PGHOST="${PGHOST-localhost}"
PGPASSWORD="${PGPASSWORD-}"
PGPORT="${PGPORT-5432}"
PGUSER="${PGUSER-postgres}"
mkdir -p data/
for brand in "${BRANDS[@]}"; do
PGPASSWORD=$PGPASSWORD psql -v brand="'${brand}'" -h "$PGHOST" -U "$PGUSER" -d "$PGDATABASE" -F ',' -A --pset footer -f alembic/examples/get_all_by_brand.sql >"data/${brand}.csv"
done
- A simple script uses the
psqlcommand to run SQL query from a.sqlfile with CSV table output mode (-Aflag) - The output of this command is saved in a CSV file within the
datadirectory of the Git repository - The script gets all the necessary database settings from the environment variables
- In our GitHub Actions, we’re going to set these environment variables from our repository secrets (note: we’ll have to add these environment variables into our repository ourselves)
Here’s the permalink to the Bash script.
GitHub Actions Workflow
Why GitHub Actions?
GitHub Actions workflow supports running on a Cron schedule. Essentially, what this means is that we can schedule our job (i.e. our script in this case) to run as short as 5 minutes intervals.
In our use case, we can use this to export our PostgreSQL query to our Google Sheets daily.
Let’s start by creating a generate_csv.yml workflow file inside the .github/workflows folder of our project directory:
name: Generate CSV
on:
workflow_dispatch:
schedule:
- cron: "30 23 * * *" # At 23:30 UTC daily
workflow_dispatchis added so that we can manually trigger our workflow from GitHub API, CLI, or browser UI- Check out Crontab Guru for Cron schedule syntax
Next, to connect to any database, we’ll need to pass the connection settings:
name: Generate CSV
on:
workflow_dispatch:
schedule:
- cron: "30 23 * * *" # <https://crontab.guru/#30_23_*_*_*>
env:
PGDATABASE: ${{ secrets.PGDATABASE }}
PGHOST: ${{ secrets.PGHOST }}
PGPASSWORD: ${{ secrets.PGPASSWORD }}
PGPORT: ${{ secrets.PGPORT }}
PGUSER: ${{ secrets.PGUSER }}
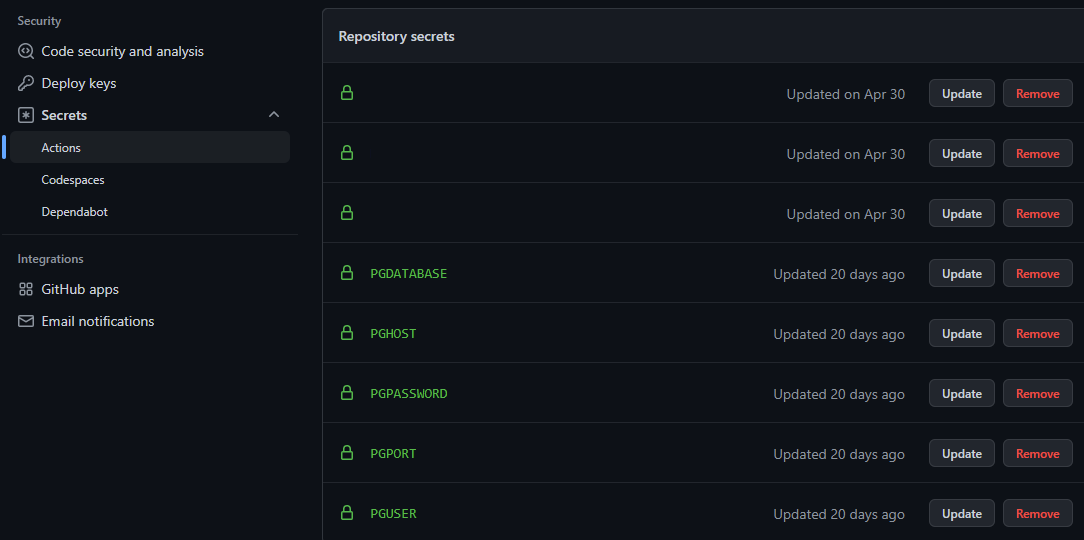
Under the same GitHub project repository Secrets setting, enter the respective environment variables under Actions:
Finally, let's create the job for us to export our PostgreSQL queries and commit them to our repository
name: Generate CSV
on:
workflow_dispatch:
schedule:
- cron: "30 23 * * *" # <https://crontab.guru/#30_23_*_*_*>
env:
PGDATABASE: ${{ secrets.PGDATABASE }}
PGHOST: ${{ secrets.PGHOST }}
PGPASSWORD: ${{ secrets.PGPASSWORD }}
PGPORT: ${{ secrets.PGPORT }}
PGUSER: ${{ secrets.PGUSER }}
jobs:
generate:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v3
- name: Install PostgreSQL # Step 1
run: |
sudo apt-get update
sudo apt-get install --yes postgresql
- name: Generate CSV # Step 2
run: scripts/generate_csv.sh
shell: bash
- name: Get current date # Step 3
id: date
run: echo "::set-output name=date::$(TZ=Asia/Singapore date +'%d %b %Y')"
- name: Commit changes # Step 4
if: ${{ success() }}
uses: EndBug/add-and-commit@v9
with:
pull: "--rebase --autostash ."
message: "chore(data): update generated csv automatically for ${{ steps.date.outputs.date }} data"
default_author: github_actions
A job in a GitHub Actions workflow can contain many steps. Different steps in GitHub Actions run in different containers as well.
- The first step is to set up and install PostgreSQL (with
psql) onto the step container - Next, we’ll add a step to run our Bash script that runs an SQL query from a file
- Optional: Get the local date-time so that we can use it as part of our commit message in Step 4
- Commit the generated CSV file from Step 2 into our repository. Here, I am using the Add & Commit GitHub Actions to commit my CSV file changes.
Why use the --autostash flag with the git pull? This allows us to automatically stash and pop the pending CSV file changes before committing and pushing them to the repository. This helps us to work around Git commit issues whereby other developers could be pushing new code changes while this job runs.
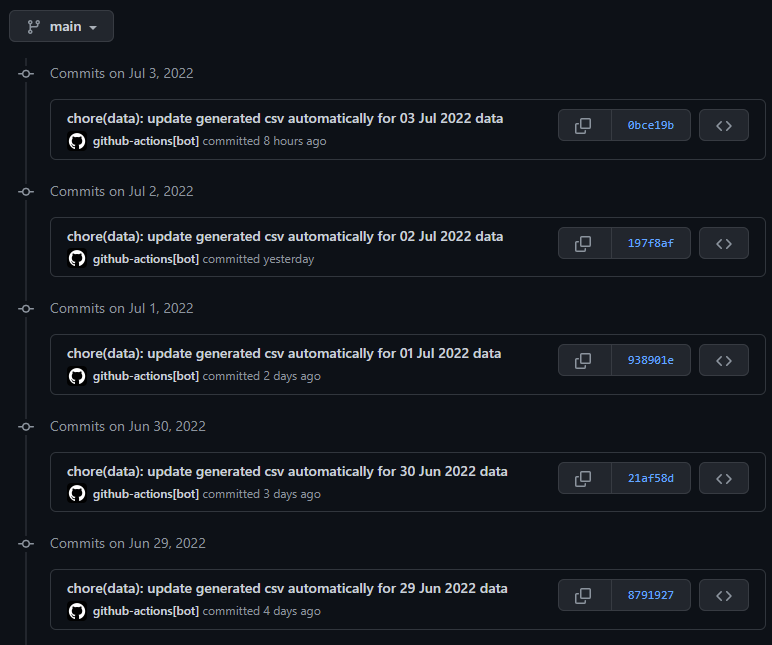
That's it! we now have a Cron job that runs every day to update our CSV file for us so that our Google Sheets can import them.
Closing Thoughts
Having GitHub — a highly available service to host our CSV file for us feels great. What’s more, having GitHub hosting this for free almost feels like some sort of a cheat.
I have also used this similar approach to run a scraper job to fetch Michelin Guide restaurants from the Michelin Guide website.
Alternatively, I have also considered using Google Sheets API to sync my data directly to Google Sheets. Given the integration efforts required, I’m glad that I stick to this very simple method.
Thanks for reading, and here's the final link to the example project.