
How I Scraped Michelin Guide Using Golang

At the beginning of the automobile era, Michelin, a tire company, created a travel guide, including a restaurant guide.
Through the years, Michelin stars have become very prestigious due to their high standards and very strict anonymous testers. Michelin Stars are incredibly coveted. Gaining one can change a chef's life; losing one, however, can change it as well.
Inspired by this Reddit post, my initial intention was to collect restaurant data from the official Michelin Guide (in CSV file format) so that anyone can map Michelin Guide Restaurants from all around the world on Google My Maps (see an example).
What follows is my thought process on how I collect all restaurant details from the Michelin Guide using Golang with the Colly framework. The final dataset is available for free to be downloaded here.
Overview
- Project goals and planning
- How not to harm the website
- The scraper and code walkthrough
Before we start, I just wanted to point out that this is not a complete tutorial about how to use Colly. Colly is unbelievably elegant yet easy to use. I’d highly recommend you go through the official documentation to get started.
Now that that is out of the way, let’s start!
Project Goals
There are 2 main objectives here —
- Collect “high-quality” data directly from the official Michelin Guide website
- Leave a minimal footprint on the website
So, what does “high-quality” mean? I want anyone to be able to use the data directly without having to perform any form of data munging. Hence, the data collected has to be consistent, accurate, and parsed correctly.
What data are we collecting?
Before starting this web-scraping project, I made sure that there are no existing APIs that provide this data, at least as of the time of writing this.
After scanning through the main page along with a couple of restaurant detail pages, I eventually settled for the following (i.e., as my column headers):
NameAddressLocationMinPriceMaxPriceCurrencyLongitudeLatitudePhoneNumberUrl(Link to the restaurant on guide.michelin.com)WebsiteUrl(The restaurant's website)Award(1 to 3 MICHELIN Stars and Bib Gourmand)
In this scenario, I am leaving out the restaurant description (see "MICHELIN Guide’s Point Of View”) as I don’t find them particularly useful. Having said that, feel free to submit a PR if you’re interested! I’d be more than happy to work with you.
On the other hand, having the restaurants’ addresses, longitude, and latitude is particularly useful when it comes to mapping them out on maps.
Here’s an example of our restaurant model:
MinPrice and MaxPrice has been replaced by Price due to the update on the MICHELIN Guide// model.go
type Restaurant struct {
Name string
Address string
Location string
MinPrice string
MaxPrice string
Currency string
Cuisine string
Longitude string
Latitude string
PhoneNumber string
Url string
WebsiteUrl string
Award string
}
https://github.com/ngshiheng/michelin-my-maps/blob/main/model/model.go
Estimations
Let’s do a quick estimation of the scraper. Firstly, what is the total number of restaurants that are expected to be present in our dataset?
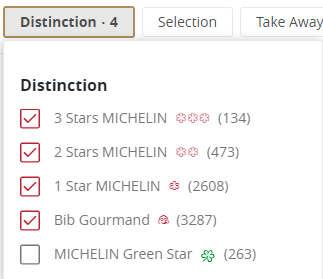
Looking at the website’s data, there should be a total of 6,502 restaurants (rows).
With each page containing 20 restaurants, our scraper will be visiting about ~325 pages; the last page of each category might not contain 20 restaurants.
The right tool, for the right job
Today, there is a handful of tools, frameworks, and libraries out there for web scraping or data extraction. Heck, there’s even a tonne of Web Scraping SaaS (e.g., Octoparse) in the market that requires no code at all.
I prefer to build my scraper due to flexibility reasons. On top of that, using a SaaS often comes with a price along with its second (often unspoken) cost — its learning curve!
Developer Tools (DevTool)
Part of the process of selecting the right library or frameworks for web scraping was to perform DevTooling on the pages.
The first step that I often take after opening up the DevTool was to immediately disable JavaScript and do a quick refresh of the page. This helps me to quickly identify how content is being rendered on the website.
Generally speaking, there are 2 main distinctions in how content is generated/rendered on a website:
- Server-side rendering
- JavaScript rendering (i.e., dynamically-loaded content)
Easy for us, the Michelin Guide website content is loaded using server-side rendering.
What if the site is rendered using JavaScript
Sidetrack for a moment — what if the site content is rendered using JavaScript? Then, we won't be able to scrape the desired data directly. Instead, we would need to check the ‘Network’ tab to see if it’s making any HTTP API calls to retrieve the content data.
Otherwise, we would need to use a JavaScript rendering (headless) browser such as Splash or Selenium to scrape the content.
Go Colly vs. Scrapy vs. Selenium
My initial thought was to use Scrapy — a feature-rich and extensible web scraping framework with Python.
However, using Scrapy in this scenario seems like overkill to me as the goal was rather simple and does not require any complex features such as using handling JavaScript rendering, middlewares, data pipelines, etc.
With this in mind, I decided to use Colly, a fast and elegant web scraping framework for Golang, due to its simplicity and the excellent developer experience it provides.
Lastly, I’m not a fan of web scraping tools such as Selenium or Puppeteer due to their relative “chunkiness” and speed. Though they are a lifesaver when it comes to scenarios where you need to scrape JavaScript-rendered websites that do not fetch data through an HTTP API.
Minimizing Footprint
The first rule of web scraping is to not harm the website. I highly recommend you to read these scraping tips provided by Colly. Essentially, these tips are pretty much tool agnostic.
Cache your responses, always
During development, it’s often inevitable to retry requests. Colly provides us with the capability to cache our responses with ease. With caching, we can:
- Greatly reduce the load on the website
- Have a much better development experience as retrying with cache is way faster
// app/app.go
// ...
cacheDir := filepath.Join(cachePath)
c := colly.NewCollector(
colly.CacheDir(cacheDir),
colly.AllowedDomains(allowedDomain),
)
Add delays between requests
When traversing through multiple pages (~325 in our case), it’s always a good idea to add a delay between requests. This allows the website to process our requests without being overloaded; we want to avoid causing any form of disruption to the site.
// app/app.go
// ...
c.Limit(&colly.LimitRule{
Delay: 2 * time.Second,
RandomDelay: 2 * time.Second,
})
Adding delays could also help to mitigate anti-scraping measures such as IP banning.
If you find yourself getting rate-limited or blocked completely, you may want to use a proxy instead. Instead of building your own proxy solution, the easiest way to do so is to use a proxy API like ScraperAPI.
The Scraper
In this section, I’ll run through only the important parts (and considerations) of the scraper code.
Selectors
Personally, I prefer to use XPath to query elements of an HTML page to extract data. If you’re into web scraping, I’d highly recommend you learn XPath; it will make your life a lot easier. Here’s my favorite cheat sheet for using XPath.
To avoid the cluttering of long ugly XPath within our main application code, I often like to put them into a separate file. You could, of course, make use of CSS selectors instead.
Entry point
To start building our scraper application, we start by identifying our entry point, i.e., the starting URLs. In our case, I’ve chosen the all-restaurants main page” (filtered by the type of Award/Distinction) as the starting URL.
// ...
type startUrl struct {
Award string
Url string
}
var urls = []startUrl{
{"3 MICHELIN Stars", "https://guide.michelin.com/en/restaurants/3-stars-michelin/"},
{"2 MICHELIN Stars", "https://guide.michelin.com/en/restaurants/2-stars-michelin/"},
{"1 MICHELIN Star", "https://guide.michelin.com/en/restaurants/1-star-michelin/"},
{"Bib Gourmand", "https://guide.michelin.com/en/restaurants/bib-gourmand"},
}
Why not simply start from guide.michelin.com/en/restaurants?
By intentionally stating my starting URLs based on the types of Michelin Awards, I would not need to extract the Michelin Award of the restaurant from the HTML. Rather, I could just fill the Award column directly based on my starting URL; one less XPath to maintain (yay)!
{kind=link}
Collectors
Our scraper application consists of 2 collectors —
- One (
collector) to parse information such as location, longitude, and latitude from the main (starting) page - Another (
detailCollector) to collect details such as an address, price, phone number, etc., from each restaurant. Also writes data in rows into our output CSV file.
How to pass context across Colly collectors
As we are only writing to our CSV file at detailCollector level, we will need to pass our extracted data from collector to detailCollector. Here’s how I did it:
// app/app.go
// ...
app.collector.OnXML(restaurantXPath, func(e *colly.XMLElement) {
url := e.Request.AbsoluteURL(e.ChildAttr(restaurantDetailUrlXPath, "href"))
location := e.ChildText(restaurantLocationXPath)
longitude := e.ChildAttr(restaurantXPath, "data-lng")
latitude := e.ChildAttr(restaurantXPath, "data-lat")
e.Request.Ctx.Put("location", location)
e.Request.Ctx.Put("longitude", longitude)
e.Request.Ctx.Put("latitude", latitude)
app.detailCollector.Request(e.Request.Method, url, nil, e.Request.Ctx, nil)
})
Code example of how you can pass context across different Colly collectors
With this, the location, longitude, and latitude information can be passed down to our detailCollector via Context (reference).
Parsers
I’ve written a couple of utility parsers to extract specific information from the extracted raw strings. As they are rather straightforward, I will not go through them.
Finally, our entire scraper app looks like this:
package app
import (
"encoding/csv"
"net/http"
"os"
"path/filepath"
"time"
"github.com/gocolly/colly"
"github.com/gocolly/colly/extensions"
"github.com/ngshiheng/michelin-my-maps/model"
"github.com/ngshiheng/michelin-my-maps/util/logger"
"github.com/ngshiheng/michelin-my-maps/util/parser"
log "github.com/sirupsen/logrus"
)
type App struct {
collector *colly.Collector
detailCollector *colly.Collector
writer *csv.Writer
file *os.File
startUrls []startUrl
}
func New() *App {
// Initialize csv file and writer
file, err := os.Create(filepath.Join(outputPath, outputFileName))
if err != nil {
log.WithFields(log.Fields{"file": file}).Fatal("cannot create file")
}
writer := csv.NewWriter(file)
csvHeader := model.GenerateFieldNameSlice(model.Restaurant{})
if err := writer.Write(csvHeader); err != nil {
log.WithFields(log.Fields{
"file": file,
"csvHeader": csvHeader,
}).Fatal("cannot write header to file")
}
// Initialize colly collectors
cacheDir := filepath.Join(cachePath)
c := colly.NewCollector(
colly.CacheDir(cacheDir),
colly.AllowedDomains(allowedDomain),
)
c.Limit(&colly.LimitRule{
Parallelism: parallelism,
Delay: delay,
RandomDelay: randomDelay,
})
extensions.RandomUserAgent(c)
extensions.Referer(c)
dc := c.Clone()
return &App{
c,
dc,
writer,
file,
urls,
}
}
// Crawl Michelin Guide Restaurants information from app.startUrls
func (app *App) Crawl() {
defer logger.TimeTrack(time.Now(), "crawl")
defer app.file.Close()
defer app.writer.Flush()
app.collector.OnResponse(func(r *colly.Response) {
log.Info("visited ", r.Request.URL)
r.Request.Visit(r.Ctx.Get("url"))
})
app.collector.OnScraped(func(r *colly.Response) {
log.Info("finished ", r.Request.URL)
})
// Extract url of each restaurant from the main page and visit them
app.collector.OnXML(restaurantXPath, func(e *colly.XMLElement) {
url := e.Request.AbsoluteURL(e.ChildAttr(restaurantDetailUrlXPath, "href"))
location := e.ChildText(restaurantLocationXPath)
longitude := e.ChildAttr(restaurantXPath, "data-lng")
latitude := e.ChildAttr(restaurantXPath, "data-lat")
e.Request.Ctx.Put("location", location)
e.Request.Ctx.Put("longitude", longitude)
e.Request.Ctx.Put("latitude", latitude)
app.detailCollector.Request(e.Request.Method, url, nil, e.Request.Ctx, nil)
})
// Extract and visit next page links
app.collector.OnXML(nextPageArrowButtonXPath, func(e *colly.XMLElement) {
e.Request.Visit(e.Attr("href"))
})
// Extract details of each restaurant and write to csv file
app.detailCollector.OnXML(restaurantDetailXPath, func(e *colly.XMLElement) {
url := e.Request.URL.String()
websiteUrl := e.ChildAttr(restarauntWebsiteUrlXPath, "href")
name := e.ChildText(restaurantNameXPath)
address := e.ChildText(restaurantAddressXPath)
priceAndCuisine := e.ChildText(restaurantpriceAndCuisineXPath)
price, cuisine := parser.SplitUnpack(priceAndCuisine, "•")
price = parser.TrimWhiteSpaces(price)
minPrice, maxPrice, currency := parser.ParsePrice(price)
phoneNumber := e.ChildText(restarauntPhoneNumberXPath)
formattedPhoneNumber := parser.ParsePhoneNumber(phoneNumber)
restaurant := model.Restaurant{
Name: name,
Address: address,
Location: e.Request.Ctx.Get("location"),
MinPrice: minPrice,
MaxPrice: maxPrice,
Currency: currency,
Cuisine: cuisine,
Longitude: e.Request.Ctx.Get("longitude"),
Latitude: e.Request.Ctx.Get("latitude"),
PhoneNumber: formattedPhoneNumber,
Url: url,
WebsiteUrl: websiteUrl,
Award: e.Request.Ctx.Get("award"),
}
log.Debug(restaurant)
if err := app.writer.Write(model.GenerateFieldValueSlice(restaurant)); err != nil {
log.Fatalf("cannot write data %q: %s\\n", restaurant, err)
}
})
// Start scraping
for _, url := range app.startUrls {
ctx := colly.NewContext()
ctx.Put("award", url.Award)
app.collector.Request(http.MethodGet, url.Url, nil, ctx, nil)
}
// Wait until threads are finished
app.collector.Wait()
app.detailCollector.Wait()
}
Feel free to check out the full source code here.
Closing Remark
Initially, I wanted to map every single Michelin-awarded restaurant on Google My Maps via its API. Unfortunately, not only does My Maps not have any API, but it only allows up to 2,000 data points. To build a map without the API, you will have to manually import our CSV on My Maps.
As a foodie myself, the project was incredibly fun to build. What was more rewarding for me was seeing people making good use of the dataset on Kaggle.
If you happen to map out the restaurants or perform any form of data analytics work with the dataset, feel free to share it with me! Before we end, if you have any questions at all, feel free to reach out.
That’s all for today, thank you for reading!