
Build Your Own: Python PDF to Text

Recently, I found myself facing the need to convert my personal PDF files to text. While there were many existing PDF to text converters available for this task, I couldn't shake the feeling of unease about uploading my private documents to unknown servers. Who knows what could happen to them or how secure they truly are?
I decided to build my own PDF to text converter (demo). Right from the get-go, I knew this was possible by using only Python.
{kind=link}
Getting Started
Before that, I must confess, I'm not particularly skilled in frontend development. So, I opted to use PyWebIO, sparing me the hassle of dealing with HTML and CSS.
Main Dependencies
To begin, I set up a new project directory named pypdf2txt and initialized it with Git and Poetry (my go-to virtual environment and package manager for Python).
I included the necessary dependencies — pdfminer.six for working with PDFs and pywebio for building the web application.
Lastly, I created a main.py file to hold the core functionality of the converter.
mkdir pypdf2txt
cd pypdf2txt
git init
poetry init
poetry add pdfminer.six pywebio
touch main.py
Optional: Dev Dependencies
I added autopep8 and ruff (instead of flake8) as development dependencies using Poetry. These will help with automatic code formatting and linting:
poetry add -D autopep8 ruff
Converting PDF to Text
NOTE: Throughout this entire walkthrough, we only have one main.py to work with.
Adding Site Description
Let’s start with something a little bit more simple, shall we? To render any output to the browser, we can simply use the pywebio.output module (reference).
# main.py
from functools import partial
from io import BytesIO, StringIO
from pathlib import Path
from pdfminer.high_level import extract_text_to_fp
from pywebio import config, session, start_server
from pywebio.input import file_upload
from pywebio.output import clear, put_buttons, put_code, put_markdown, toast, use_scope
from pywebio.session import download, run_js
def render_description():
description = """
# Pypdf2: Convert PDF to Text
A simple Python web service that allows you to convert your PDF documents to text.
Extract text from PDF files without compromising **privacy**, **security**, and **ownership**.
## Features
- Converts PDF documents to text
- Simple and easy-to-use web interface
- Fast and efficient text extraction
"""
put_markdown(description)
In the render_description function, I define the app's description using a markdown-formatted string.
Then, I use put_markdown from the pywebio.output module to display the description in the web interface.
Setting Up the Web App
This is the main function that brings everything together:
# ... (rest of the code)
def main():
session.run_js(
'WebIO._state.CurrentSession.on_session_close(()=>{setTimeout(()=>location.reload(), 4000})',
)
render_description()
# process_pdf() # TODO: create & uncomment later
if __name__ == "__main__":
start_server(main, port=8080)
It starts the PyWebIO server, runs the JavaScript code for auto-reloading the page on session close, renders the initial description of the app, and invokes the process_pdf function to handle the PDF to text conversion.
Now, when you run the app, it will render the description at the start:
poetry run python3 main.py
File Upload
Next, I needed to upload the PDF file through the web interface. Let’s create a function name process_pdf utilizing the file_upload API. I found a handy example of file upload in the PyWebIO documentation, and with a bit of copy-pasting, I was well on my way:
# ... (rest of the code)
def process_pdf():
put_markdown(
"""
## Convert PDF To Text
""",
)
while True:
pdf_file = file_upload(
"Select PDF",
accept="application/pdf",
max_size="10M",
multiple=False,
help_text="sample.pdf",
)
text_output = extract_text_from_pdf(pdf_file) # TODO: work on this later
text_filename = f"{Path(pdf_file['filename']).stem}.txt"
# ... (rest of the code)
First, I added a "Convert PDF To Text” heading to the UI, making it clear what the app was designed to do.
The file_upload function handled the file selection, ensuring that only PDFs were accepted and imposing a reasonable file size limit of 10MB — for now.
In the future, we could configure this based on the deployment server's available RAM.
Extracting Text from PDF
Once the user uploaded the PDF file, the extract_text_from_pdf function swung into action. Here's the code snippet for extracting text from the uploaded PDF:
# ... (rest of the code)
from pdfminer.high_level import extract_text_to_fp
def extract_text_from_pdf(pdf_file):
pdf_buffer = BytesIO(pdf_file['content'])
text_buffer = StringIO()
extract_text_to_fp(pdf_buffer, text_buffer)
return text_buffer.getvalue()
# ... (rest of the code)
Here's where the magic happened. To extract text from the PDF, I utilized the extract_text_to_fp API from pdfminer to do the job. The concise PDFMiner documentation guided me through the process.
Keeping Output Area Clean
To maintain a clean user experience, I encapsulated the text output and download button in a "scope" using PyWebIO's use_scope function (reference).
This allowed me to clear the specified output area every time a new file was uploaded, ensuring that each conversion was separate and didn't clutter the interface.
# ... (rest of the code)
def process_pdf():
put_markdown(
"""
## Convert PDF To Text
""",
)
while True:
pdf_file = file_upload(
"Select PDF",
accept="application/pdf",
max_size="10M",
multiple=False,
help_text="sample.pdf",
)
clear('text-output-area') # NOTE: to clear previous text output
text_output = extract_text_from_pdf(pdf_file)
text_filename = f"{Path(pdf_file['filename']).stem}.txt"
with use_scope('text-output-area'):
put_markdown(
"""
### Text Output
""",
)
put_code(text_output, rows=10)
put_buttons(
[
"Copy to Clipboard",
'Click to Download',
],
onclick=[
partial(
copy_to_clipboard, # TODO: create later
text=text_output
),
partial(
click_to_download, # TODO: create later
filename=text_filename,
text=text_output.encode(),
),
],
)
# ... (rest of the code)
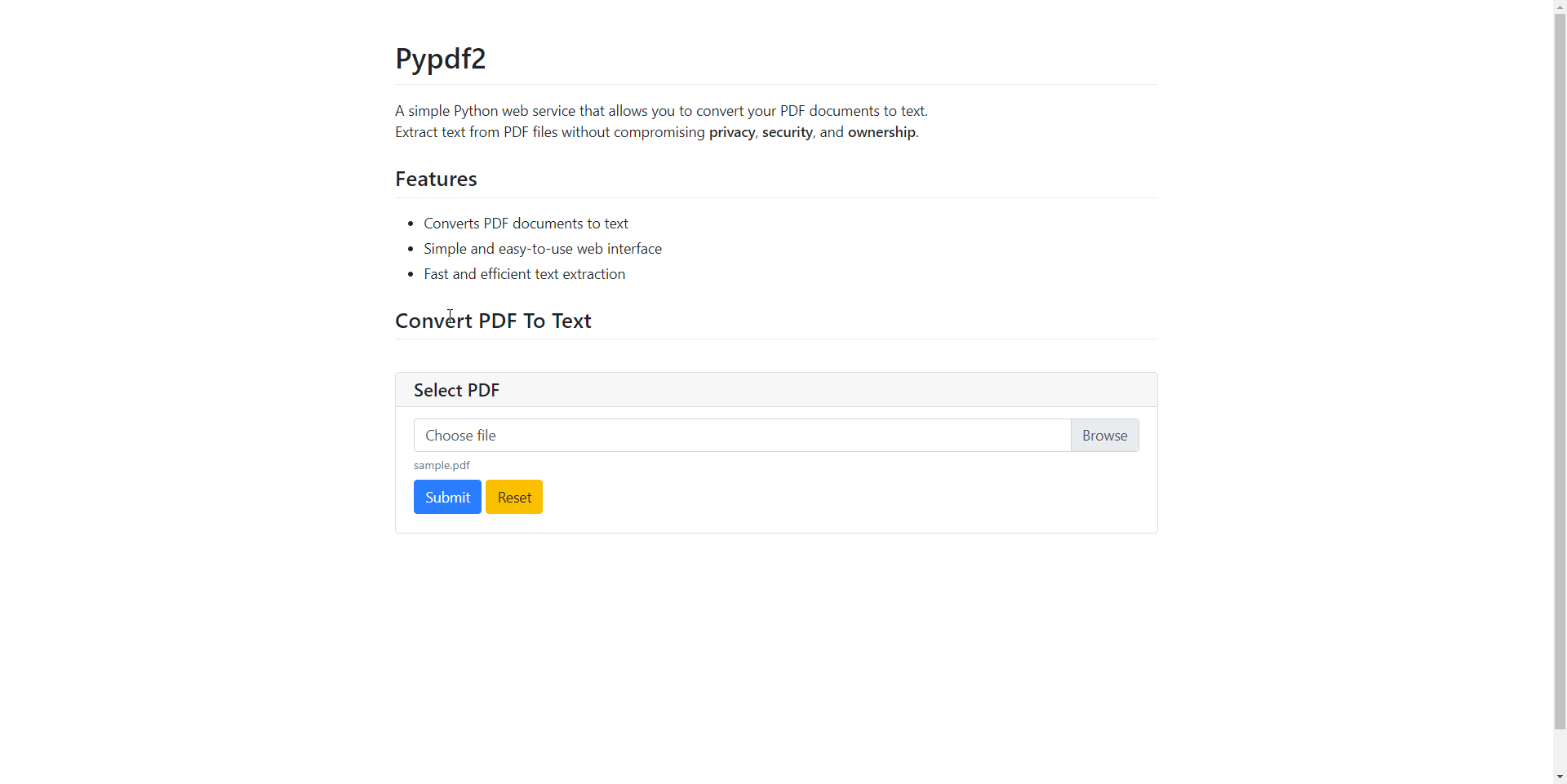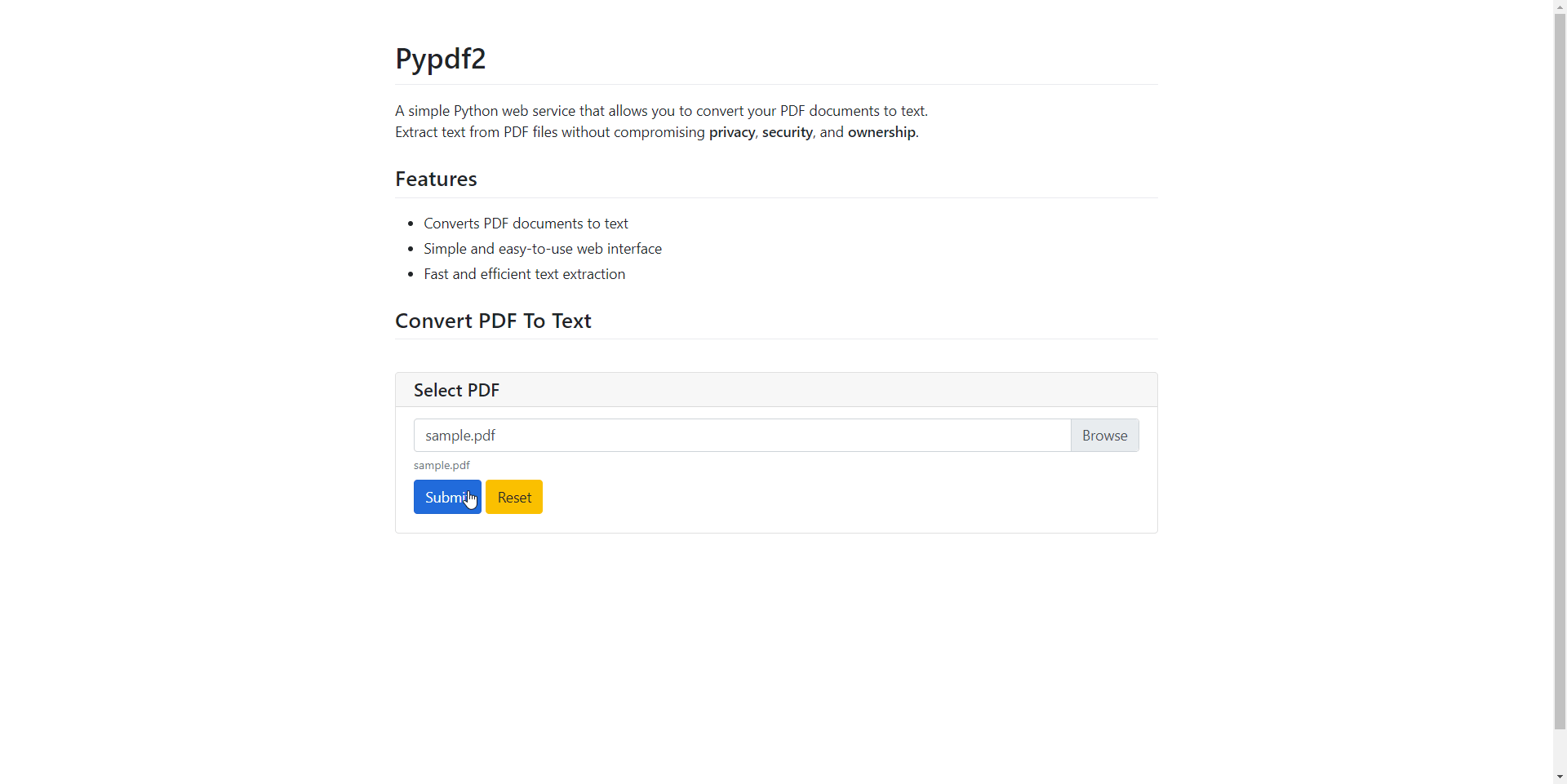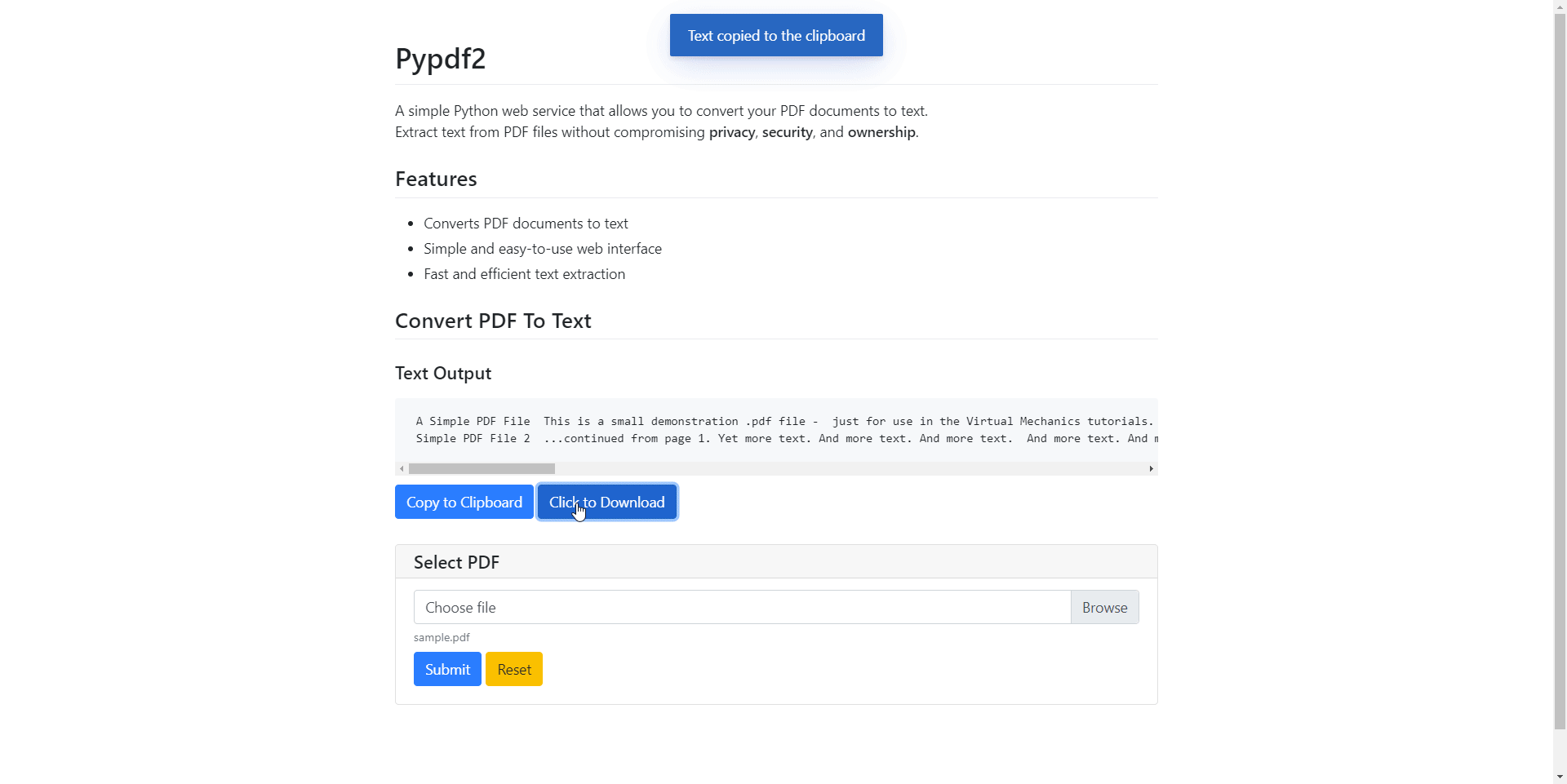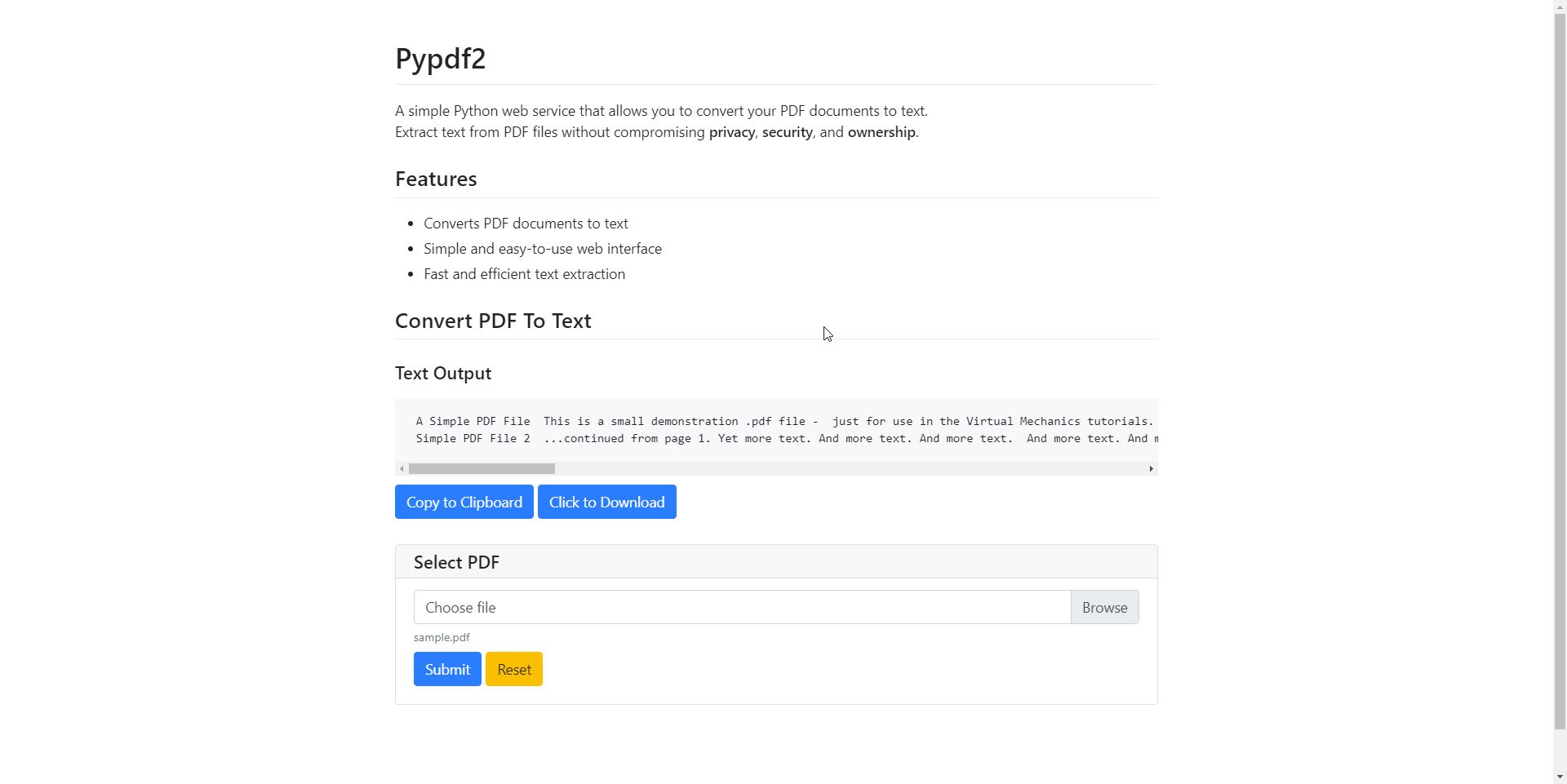
Download Text Output
Implementing a “Click to Download” feature for our app is super straightforward. In fact, you can choose between using put_file (reference) or download (reference).
I chose the latter because I wanted it to be a button instead of a link:
# ... (rest of the code)
def click_to_download(filename: str, text: bytes):
download(
filename,
text,
)
toast('Text file downloaded')
# ... (rest of the code)
With this, users can download the output text with a simple click of a button.
Copy to Clipboard
Lastly, let’s work on our “Copy to Clipboard” feature. This is where things are a little bit more tricky.
I learned that PyWebIO doesn't natively support this copy-to-clipboard function. Yet, the demo above showcased its presence, sparking my determination to uncover its implementation.
Despite my thorough search through the official documentation, the feature remained elusive. However, my experience has led me to Sourcegraph, where I unearthed the secrets behind its clever implementation. Oh, the joy of discovery!
After taking inspiration from PyWebIO's demo example, here’s what I arrived at:
# ... (rest of the code)
def copy_to_clipboard(text: str):
clipboard_setup = """
window.writeText = function(text) {
const input = document.createElement('textarea');
input.style.opacity = 0;
input.style.position = 'absolute';
input.style.left = '-100000px';
document.body.appendChild(input);
input.value = text;
input.select();
input.setSelectionRange(0, text.length);
document.execCommand('copy');
document.body.removeChild(input);
return true;
}
"""
run_js(clipboard_setup)
run_js("writeText(text)", text=text)
toast('Text copied to the clipboard')
# ... (rest of the code)
When the user clicks the "Copy to Clipboard" button, the JavaScript code within copy_to_clipboard sets up a temporary textarea, copies the text to it, selects the content, and executes the copy command.
As a result, the extracted text is now ready for pasting elsewhere, and a toast notification confirms the successful copy operation. Yay!
Full Code
You may find the full code example here:
 ngshiheng
ngshihengClosing Thoughts
Congratulations! You now have the power of converting PDF to text at your fingertips, without sacrificing privacy, security, and ownership.
I remember the first time I stumbled upon PyWebIO, and I was immediately intrigued by its promise of creating web apps with just a few lines of Python code. While it might not suit complex projects, for simple tools, it's amazing.
If I were to build a GUI application, I would have gone for something like PyQt. Today, I’d say no more GUI frameworks; just one browser app is all you need.
Happy building!