
I Built My Own TinyURL. Here’s How I Did It

Designing a URL shortener such as TinyURL and Bitly is one of the most common system design interview questions in software engineering.
While meddling around with Cloudflare Worker to sync the Daily LeetCode Challenge to my Todoist, it gave me an idea to build an actual URL shortener that can be used by anyone.
What follows is my thought process with code examples on how we can create a URL shortener using Cloudflare Worker. If you would like to follow through, you would need a Cloudflare account and use the Wrangler CLI.
TL;DR
- Building a URL shortener for free with Cloudflare Worker and KV
- Project requirements and limitations planning
- Short URL UUID generation logic
- Live demo at s.jerrynsh.com
- GitHub repository
Before we begin, do not get your hopes up too high. This is not a guide on:
- How to tackle an actual system design interview
- Building a commercial-grade URL shortener like TinyURL or Bitly
But, rather a proof of concept (POC) of how one builds an actual URL shortener service using serverless computing. So, throw “scalability”, “partitioning”, “replicas”, etc. out of the window and buckle up.
I hope you will find this post insightful and entertaining to read!
Requirements
Like any system design interview, let’s start by defining some functional and non-functional requirements.
Functional
- Given a URL, our service should return a unique and short URL of it. E.g.
https://jerrynsh.com/how-to-write-clean-code-in-python/→s.jerrynsh.com/UcFDnviQ - Whenever a user tries to access
s.jerrynsh.com/UcFDnviQ, the user would be directed back to the original URL. - The UUID (I sometimes call it URL key because it is the key of our storage object) should adhere to the Base62 encoding scheme (26 + 26 + 10):
1. A lower case alphabet 'a' to 'z', a total of 26 characters
2. An upper case alphabet 'A' to 'Z', a total of 26 characters
3. A digit '0' to '9', a total of 10 characters
4. In this POC, we will not be supporting custom short links- The length of our UUID should be ≤ 8 characters as 62⁸ would give us about ~218 trillion possibilities.
- The short URL generated should never expire.
Non-Functional
- Low latency
- High availability
Budget, Capacity, & Limitations Planning
The aim is simple — I want to be able to host this service for free. As a result, our constraints depend largely on Cloudflare Worker’s pricing and platform limits.
At the time of writing this, the constraints per account to host our service for free are:
- 100k requests/day at 1k requests/min
- CPU runtime not exceeding 10ms
Like most URL shorteners, our application is expected to encounter high reads but relatively low writes. To store our data, we will be using Cloudflare KV, a key-value data store that supports high read with low latency — perfect for our use case.
Moving on from our previous constraints, the free tier of KV and limit allows us to have:
- 100k reads/day
- 1k writes/day
- 1 GB of stored data (key size of 512 bytes; value size of 25 MiB)
How many short URLs can we store
With 1 GB of free maximum stored data limit in mind, let’s try to estimate how many URLs can we possibly store. Here, I am using this tool to estimate the byte size of the URL:
- 1 character is 1 byte
- Since our UUID should only be a maximum of 8 characters, we have no issue with the key size limit.
- For the value size limit on the other hand — I am making a calculated guess that the maximum URL size should average around 200 characters. Thus, I believe it is safe to assume that each stored object should be an average of ≤400 bytes, which is very well below 25 MiB.
- And finally, with 1 GB to work with, our URL shortener can support up to a total of 2,500,000 (1 GB divided by 400 bytes) short URLs.
- I know, I know. 2.5 million URLs is not a lot.
Looking back, we could have made the length of our UUID ≥ 4 instead of 8 as 62⁴ possibilities are well more than 2.5 million. Having that said, let’s stick with a UUID with a length of 8.
Overall, I would say that the free tier for Cloudflare Worker and KV is pretty generous and decent enough for our POC. Do note that the limits are applied on a per-account basis.
Storage/Database
As I mentioned earlier, we will be using Cloudflare KV as the database to store our shortened URLs as we are expecting more reads than writes.
Eventually Consistent
One important note — while KV can support exceptionally high read globally, it is an eventually consistent storage solution. In other words, any writes (i.e. creating a short URL) may take up to 60 seconds to propagate globally — this is a downside we are okay with.
Through my experiments, I have yet to encounter anything more than a couple of seconds.
Atomic Operation
Reading about how KV works, KV is not ideal for situations that require atomic operations (e.g. a bank transaction between two account balances). Lucky for us, this does not concern us at all.
For our POC, the key of our KV would be a UUID that follows after our domain name (e.g. s.jerrynsh.com/UcFDnviQ) while the value would consist of the long URL given by the users.
Creating a KV
To create a KV, simply run the following commands with Wrangler CLI.
# Production namespace:
wrangler kv:namespace create "URL_DB"
# This namespace is used for `wrangler dev` local testing:
wrangler kv:namespace create "URL_DB" --previewFor creating these KV namespaces, we also need to update our wrangler.toml file to include the namespace bindings accordingly. You can view your KV’s dashboard by visiting https://dash.cloudflare.com/<your_cloudflare_account_id>/workers/kv/namespaces.
Short URL UUID Generation Logic
This is probably the most important aspect of our entire application.
Based on our requirements, the aim is to generate an alphanumeric UUID for each URL whereby the length of our key should be no more than 8 characters.
In a perfect world, the UUID of the short link generated should have no collision. Another important aspect to consider is — what if multiple users shorten the same URL? Ideally, we should also check for duplication.
Let’s consider the following solutions:
1. Using a UUID generator
This solution is relatively straightforward to implement. For every new URL that we encounter, we simply call our UUID generator to give us a new UUID. We would then assign the new URL with the generated UUID as our key.
In the case whereby the UUID has already existed (collision) in our KV, we can keep retrying. However, we do want to be mindful of retrying as it can be relatively expensive.
Furthermore, using a UUID generator would not help us when it comes to dealing with duplications in our KV. Looking up the long URL value within our KV would be relatively slow.
2. Hashing the URL
On the other hand, hashing a URL allows us to check for duplicated URLs because passing a string (URL) through a hashing function would always yield the same result. We can then use the result (key) to look up in our KV to check for duplication.
Assuming that we use MD5, we would end up with ≥ 8 characters for our key. So, what if we could just take the first 8 bytes of the generated MD5 hash? Problem solved right?
Not exactly. Hashing function would always produce collisions. To reduce the probability of collision, we could generate a longer hash. But, it would not be very user-friendly. Also, we want to keep our UUID ≤ 8 characters.
3. Using an incremental counter
Possibly the simplest yet most scalable solution in my opinion. Using this solution, we will not run into issues with collision. Whenever we consume the entire set (from 00000000 to 99999999), we can simply increment the number of characters in our UUID.
Nonetheless, I do not want users to be able to randomly guess a short URL by simply visiting s.jerrynsh.com/12345678. So, this solution is out of the question.
Finally
There are a lot of other solutions (e.g. pre-generate a list of keys and assign an unused key when a new request comes in) out there with their pros and cons.
For our POC, we are going with solution 1 as it is straightforward to implement and I am fine with duplicates. To cope with duplicates, we could cache our users’ requests to shorten URLs.
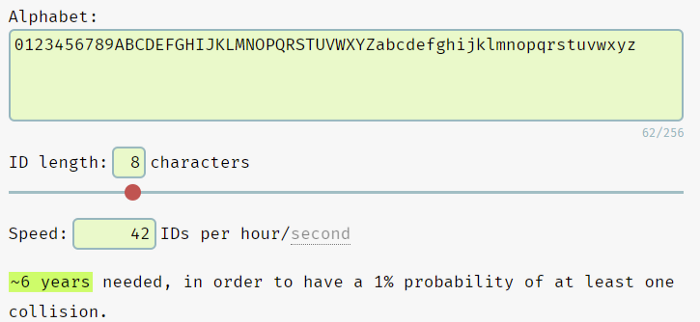
Nano ID
To generate a UUID, we are using the nanoid package. To estimate our rate of collision, we can use the Nano ID collision calculator:
Okay enough talk, let’s write some code!
To handle the possibility of collision, we simply have to keep retrying:
// utils/urlKey.js
import { customAlphabet } from 'nanoid'
const ALPHABET = '0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz'
/*
Generate a unique `urlKey` using `nanoid` package.
Keep retrying until a unique urlKey which does not exist in the URL_DB.
*/
export const generateUniqueUrlKey = async () => {
const nanoId = customAlphabet(ALPHABET, 8)
let urlKey = nanoId()
while ((await URL_DB.get(urlKey)) !== null) {
urlKey = nanoId()
}
return urlKey
}API
In this section, we will define the API endpoints that we would like to support. This project is initialized using the itty-router worker template — it helps us with all the routing logic:
wrangler generate <project-name> https://github.com/cloudflare/worker-template-router
The entry point of our project lies in the index.js:
// index.js
import { Router } from 'itty-router'
import { createShortUrl } from './src/handlers/createShortUrl'
import { redirectShortUrl } from './src/handlers/redirectShortUrl'
import { LANDING_PAGE_HTML } from './src/utils/constants'
const router = Router()
// GET landing page html
router.get('/', () => {
return new Response(LANDING_PAGE_HTML, {
headers: {
'content-type': 'text/html;charset=UTF-8',
},
})
})
// GET redirects short URL to its original URL.
router.get('/:text', redirectShortUrl)
// POST creates a short URL that is associated with its an original URL.
router.post('/api/url', createShortUrl)
// 404 for everything else.
router.all('*', () => new Response('Not Found', { status: 404 }))
// All incoming requests are passed to the router where your routes are called and the response is sent.
addEventListener('fetch', (e) => {
e.respondWith(router.handle(e.request))
})
In the name of a better user experience, I have created a simple HTML landing page that anyone could use; you can get the landing page’s HTML here.
Creating short URL
To start, we need a POST endpoint (/api/url) that calls createShortUrl that parses the originalUrl from the body and generates a short URL from it.
Here’s the code example:
// handlers/createShortUrl.js
import { generateUniqueUrlKey } from '../utils/urlKey'
export const createShortUrl = async (request, event) => {
try {
const urlKey = await generateUniqueUrlKey()
const { host } = new URL(request.url)
const shortUrl = `https://${host}/${urlKey}`
const { originalUrl } = await request.json()
const response = new Response(
JSON.stringify({
urlKey,
shortUrl,
originalUrl,
}),
{ headers: { 'Content-Type': 'application/json' } }
)
event.waitUntil(URL_DB.put(urlKey, originalUrl))
return response
} catch (error) {
console.error(error, error.stack)
return new Response('Unexpected Error', { status: 500 })
}
}To try this out locally (you can use wrangler dev to start the server locally), use the Curl command below:
curl --request POST \\
--url http://127.0.0.1:8787/api/url \\
--header 'Content-Type: application/json' \\
--data '{
"originalUrl": "https://www.google.com/"
}'
Redirecting short URL
As a URL shortening service, we want users to be able to redirect to their original URL when they visit a short URL:
// handlers/redirectShortUrl.js
export const redirectShortUrl = async ({ params }) => {
const urlKey = decodeURIComponent(params.text)
const originalUrl = await URL_DB.get(urlKey)
if (originalUrl) {
return Response.redirect(originalUrl, 301)
}
return new Response('Invalid Short URL', { status: 404 })
}How about deletion? Since the user does not require any authorization to shorten any URL, the decision was made to move forward without a deletion API as it makes no sense that any user can simply delete another user’s short URL.
To try out our URL shortener locally, simply run wrangler dev.
Bonus: dealing with duplication with caching
NOTE: Currently, this only works with a custom domain.
What happens if a user decides to repeatedly shorten the same URL? We wouldn’t want our KV to end up with duplicated URLs with unique UUID assigned to them right?
To mitigate this, we could use a cache middleware that caches the originalUrl submitted by users using the Cache API:
import { URL_CACHE } from '../utils/constants'
export const shortUrlCacheMiddleware = async (request) => {
const { originalUrl } = await request.clone().json()
if (!originalUrl) {
return new Response('Invalid Request Body', {
status: 400,
})
}
const cache = await caches.open(URL_CACHE)
const response = await cache.match(originalUrl)
if (response) {
console.log('Serving response from cache.')
return response
}
}To use this cache middleware, simply update our index.js accordingly:
// index.js
...
router.post('/api/url', shortUrlCacheMiddleware, createShortUrl)
...
Finally, we need to make sure that we update our cache instance with the original URL upon shortening it:
// handlers/createShortUrl.js
import { URL_CACHE } from '../utils/constants'
import { generateUniqueUrlKey } from '../utils/urlKey'
export const createShortUrl = async (request, event) => {
try {
const urlKey = await generateUniqueUrlKey()
const { host } = new URL(request.url)
const shortUrl = `https://${host}/${urlKey}`
const { originalUrl } = await request.json()
const response = new Response(
JSON.stringify({
urlKey,
shortUrl,
originalUrl,
}),
{ headers: { 'Content-Type': 'application/json' } }
)
const cache = await caches.open(URL_CACHE) // Access our API cache instance
event.waitUntil(URL_DB.put(urlKey, originalUrl))
event.waitUntil(cache.put(originalUrl, response.clone())) // Update our cache here
return response
} catch (error) {
console.error(error, error.stack)
return new Response('Unexpected Error', { status: 500 })
}
}During my testing with wrangler dev, it seems like the Worker cache does not work locally or on any worker.dev domain.
The workaround to test this is to run wrangler publish to publish the application on a custom domain. You can validate the changes by sending a request to the /api/url endpoint while observing the log via wrangler tail.
Deployment
No side project is ever done without hosting it right?
Before publishing your code you need to edit the wrangler.toml file and add your Cloudflare account_id inside. You can read more information about configuring and publishing your code can be found in the official documentation.
To deploy and publish any new changes to your Cloudflare Worker, simply run wrangler publish. To deploy your application to a custom domain, check out this short clip.
In case you are lost halfway through, you can always check out the GitHub repository here. And that’s it!
Final Thoughts
Honestly, this is the most fun I have had in a while — researching, writing, and building this POC at the same time. There’s a lot more on top of my mind that we could have done for our URL shortener; just to name a few:
- Storing metadata such as creation date, number of visits
- Adding authentication
- Handle short URL deletion and expiration
- Analytics for users
- Custom link
A problem that most URL shortening services face is that short URLs are often abused to lead users to malicious sites. I think it’d be an interesting topic to look further into.
That’s all for today! Cheers!
Check out how I set up a CI/CD pipeline for this Atomic URL.