
How I Built A Craft Beer Search Engine For Free

Craft beers are delicious. Expensively delicious. When I first came to Singapore, I was introduced to the wonders of craft beers. Coming from Malaysia, I felt spoiled by the number of choices available here.
Soon, my friends and I got caught up with the craft beer fever, but there was one problem — craft beers are relatively expensive.
Growing up in a frugal family, I would spend hours browsing online, looking for the best bang for my buck. Needless to say, the process was super exhausting and slowly turns into frustration.
So then I thought, why not just create a search engine for craft beers?
Preface
In short, I am sharing my decisions and thought process of how I came about creating Burplist, a fast and simple search engine for craft beers in Singapore.
Rather than slamming in code examples in this post, I write about a high-level overview of how and why things are done in such a manner. So, you may find links to articles in different sections of this post on the know-how of how some steps were achieved, including the source code for the crawlers and the site.
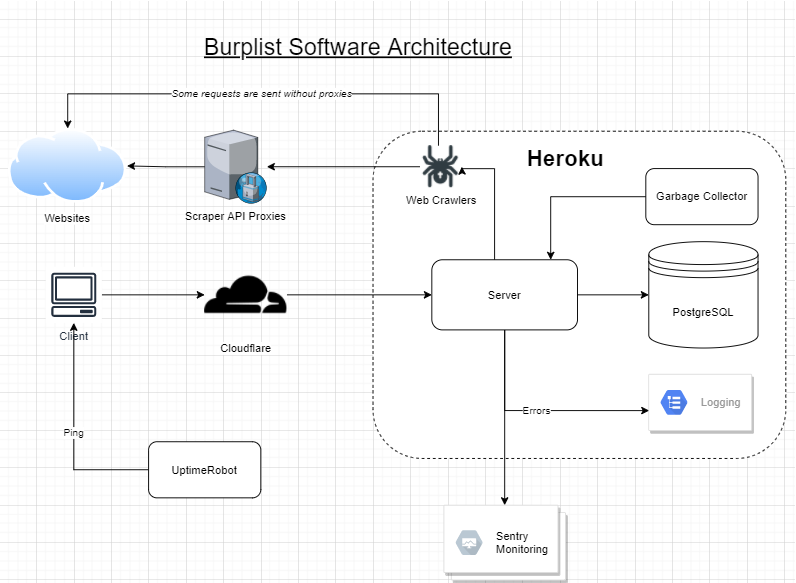
Goals
There are only 4 things that I had in my mind:
- The search has to be fast
- Price information has to be accurate, and updated daily
- The cost of running the site has to be as low as possible (ideally free)
- Do no harm to any sites
With these 4 goals in my mind, I started ideating and building Burplist.
Sources
So, where can I buy craft beers online from Singapore?
A quick Google search for the phrase “craft beer in Singapore” yields a couple of sites to purchase craft beers from. Apart from these independent craft beer sellers (Thirsty), there are also large e-commerce platforms locally such as Shopee or Lazada.
Grocery stores also sell a good selection of craft beers which often come with discounts and promotions. With these sources in mind, we are blessed with over 10 different sites to choose from.
Let’s hop on to the tech stacks!
Web Crawlers
As part of the goal, the search feature has to be fast. With this in mind, it means that we have to store the information on our servers rather than querying the price information on demand.
Here, I’ve opted to use web scraping to gather the information during the off-rush hours. The information is then stored on a hosted database, allowing users to query data from it in a relatively fast manner.
Python Scrapy
Burplist has well over 10 unique crawlers (spiders). Each crawler is responsible to extract information from a specific site. The web crawlers are built using Scrapy, an incredibly fast and powerful Python web crawling framework. It works super well in a mid to large-scale project and it can scale relatively easily. Though, it does come with some learning curves of its own.
Web scraping can yield pretty inconsistent and unexpected results which often require a lot of post-processing and cleansing. Scrapy has a built-in concept of item pipeline which eases the post-processing of the information that we find. This become a huge reason why Scrapy was chosen for this project.
At Burplist, Scrapy pipelines are used to:
- Clean data. Normalizing data across multiple sources can be tedious
- Validate data. Ensure that the item (information) saved contains certain fields
- Check for duplicates
- Storing items in our database
Python became the main programming language of choice in this project, mainly because we use Scrapy.
If you are interested, the web crawler source code can be found here. I have also documented a couple of useful tips while working with Scrapy here.
Respecting rate limits
The first rule of web scraping is to not harm the website. In this spirit, the crawlers are scheduled to run once daily during off-peak hours and off-peak hours only.
That aside, I made sure that the crawler always respects the rate limit so that we avoid hammering the site with unnecessary requests.
As development work is an iterative process, we would unintentionally increase the server load for the site that we are scraping. To avoid such behavior, HttpCacheMiddleware can be used to cache every request made by our crawlers.
Hosting, Database & Scheduler
The project has to run as cheaply as possible, ideally being free for everyone, myself included.
With this in mind, I immediately turned my head to Heroku. Heroku has been a lifesaver for me as a developer, the free tier for Heroku is incredibly generous. With a verified credit card, any Heroku user can receive a total of 1,000 free dyno hours per month.
You may find more comprehensive steps that I have documented on how to deploy Scrapy Spiders for free on the cloud here.
Heroku Schedulers
To keep the price information fresh, Burplist uses the free Heroku Scheduler add-on to run the crawlers daily during off-peak hours. The usage of the Heroku Schedule counts towards our monthly usage of dyno hours, which is technically free for our use case as mentioned before.
Crawlers at Burplist essentially take about an hour to complete their job which means we only use about 30/1,000 free dyno hours a month.
Though Heroku claims that the scheduler does not guarantee that the job will execute on time or at all, so far I have never had any issues with it.
Heroku PostgreSQL
PostgreSQL has always been my go-to for relational databases, mostly because I am the most comfortable with it. I chose to use a relational database for this project because of how the information is being stored (structured data).
In terms of cloud-hosted database solutions, Heroku Postgres’s Hobby Dev tier provides us with a 10,000 rows limit. As we store the pricing history of each of the items we scrapped, there’s no doubt that the 10,000 rows limit would be exceeded in no time.
To keep the row limits in check, a garbage collector service runs every week (with Heroku Scheduler) to remove staled products that were removed by retailers. Well, we have no use for those stale data anyway.
To date, we have yet to exceed this limit. With scalability in mind, scaling Heroku PostgreSQL isn’t going to be much of a problem soon. In any case, we can easily swap out to AWS RDS if things get serious.
Frontend
As a backend developer, front-end web development isn’t my strongest suit. For this project, I wanted to get things out to the public as quickly as possible.
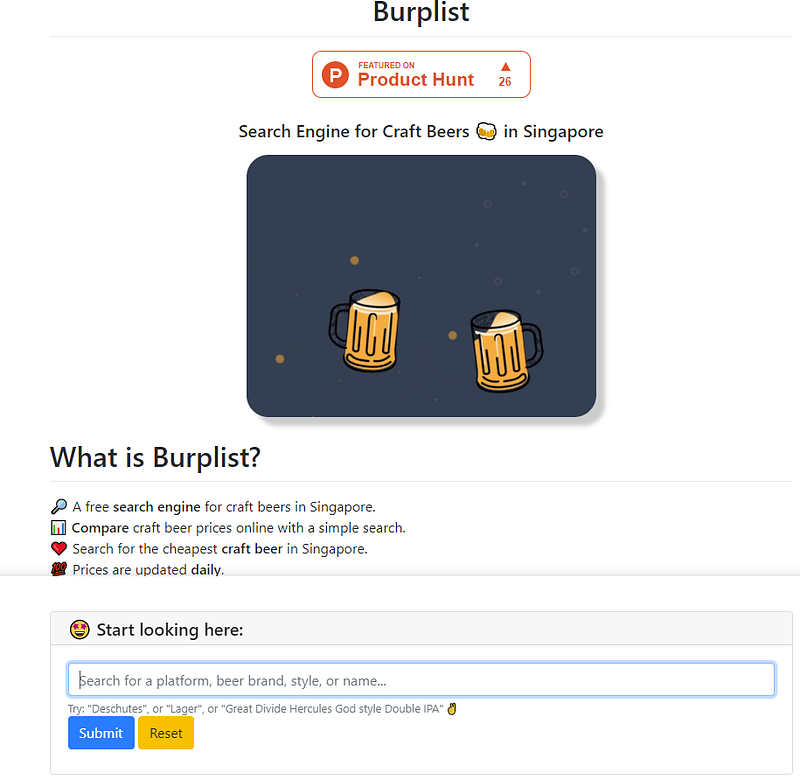
While the previous version of Burplist doesn’t have the best UI or anything remotely close to being called good-looking, it was proudly made purely with Python.
The web app was made using PyWebIO, which is an alternative to Steamlit and Anvil. I was able to build a simple and interactive web app simply with just Python and Markdown, without using any HTML and CSS. Cool.
The web app is hosted on Heroku too. As Burplist runs for 24 hours a day, We would only consume 744/1,000 of our free dyno hours.
Great, we got the site runs for free, for everyone. Feel free to check out the frontend repository here.
Monitoring & Logging
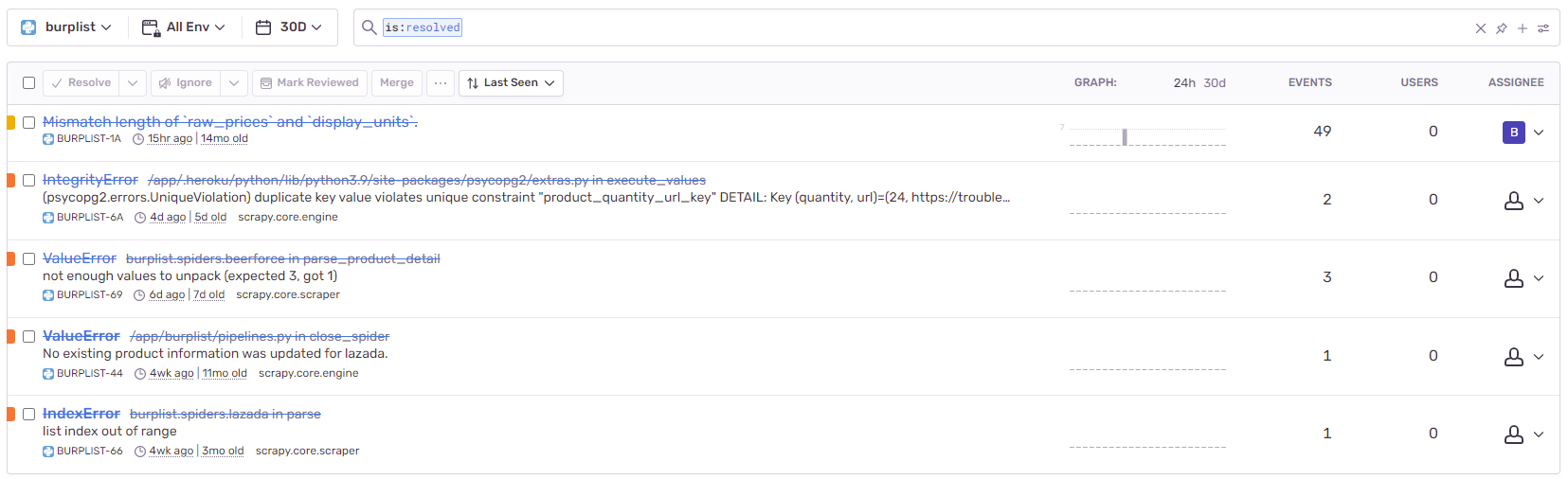
One of the key challenges faced when developing Burplist is the ever-changing website structure. Today, websites are always subjected to design (HTML, CSS) changes to provide a better user experience.
In this scenario, our crawler would run into situations where the way to extract the information suddenly changes. In this project, we use Sentry to monitor for any errors given by our web crawlers. For our usage, Sentry is practically free and super easy to integrate with Scrapy or any Python project.
As for logging, I am using the Coralogix Logging add-on provided by Heroku.
Cold Start & Downtime
One of the key cons of using Heroku’s free tier with its free dyno hours is that it will sleep if the site receives no traffic in 30 minutes. When a new user visits Burplist, he or she would experience a cold start. This is a horrible user experience.
Kaffeine
To cope with this, you can use Kaffeine which pings a Heroku app every 30 minutes so that it will never go to sleep. Or perhaps, you could make your site ping-er.
UpTimeRobot
For Burplist, I am using UpTimeRobot, which is a free website monitoring service that alerts the site owner whenever the site goes down. What happens behind the scene is that UpTimeRobot would ping Burplist every 5 minutes.
Great, now we have a monitoring service along with a site ping-er!
Proxy
While scraping large e-commerce sites, it is pretty common for us to run into anti-scraping countermeasures. Rather than building our own proxy infrastructure to cope with this, I use Scraper API (referral link) to abstract all the complexities of managing my own proxies.
Again, cost plays an important role here. The free tier provided by Scraper API fits my use case here.
Closing Thoughts
I absolutely love building side projects. I built Burplist out of my frustration of having to browse across multiple websites just to get the best deals for my favorite craft beers. It took me about 6 weeks to finish building the MVP.
I am glad that I got the site up and running which cost me practically nothing. Well, except for the domain name. As a huge fan of productivity apps, I certainly hope that this helps to save people a bunch of time.
If you are into data science and you are interested in working on some charts, do let me know! I’d be more than happy to share what I have!
Thanks for reading! I hope you enjoyed it! Cheers!
P/S: If you're looking for price monitoring for commercial beers in Singapore instead, check out Fareview.